Redshiftハンズオン!Redshiftの基本操作(セットアップ、基本クエリ操作、テーブルの最適化)を実行しよう【初心者向け】
おはようございます!
ベンジャミンの木村です!
今回、Redshiftの簡単なハンズオンを作成しました!Redshift初心者にも理解できる内容となっておりますので、実施していただけますと幸いです。
目次
- ハンズオンの内容
- 1. 事前作業
- 2. Redshiftクラスターの作成
- 3. クラスターへの接続
- 4. テーブルの作成とデータのロード
- 5. COPYコマンドで大量データをロード
- 6. クエリの最適化
- まとめ
ハンズオンの内容
今回のハンズオンでは、まずRedshiftクラスターを作成し、SQLを実行してテーブルおよびレコードを作成します。(項番1から4の内容)

その後、S3のCSVデータをCOPYコマンドでRedshiftにロードする処理を実行します。(項番5の内容)

最後に、Redshiftテーブルの最適化処理を実行します。(項番6の内容)

1. 事前作業
下記リソースは事前に作成ください
- VPCやサブネットなどの基本的なネットワーク設定
- Redshift用のセキュリティグループ
- インバウンドは「接続元のIPアドレス」と「5439ポート」を開放してください。
2. Redshiftクラスターの作成
2-1. Redshiftサービスの Console画面へ移動する
https://ap-northeast-1.console.aws.amazon.com/redshiftv2/home?region=ap-northeast-1#/clusters
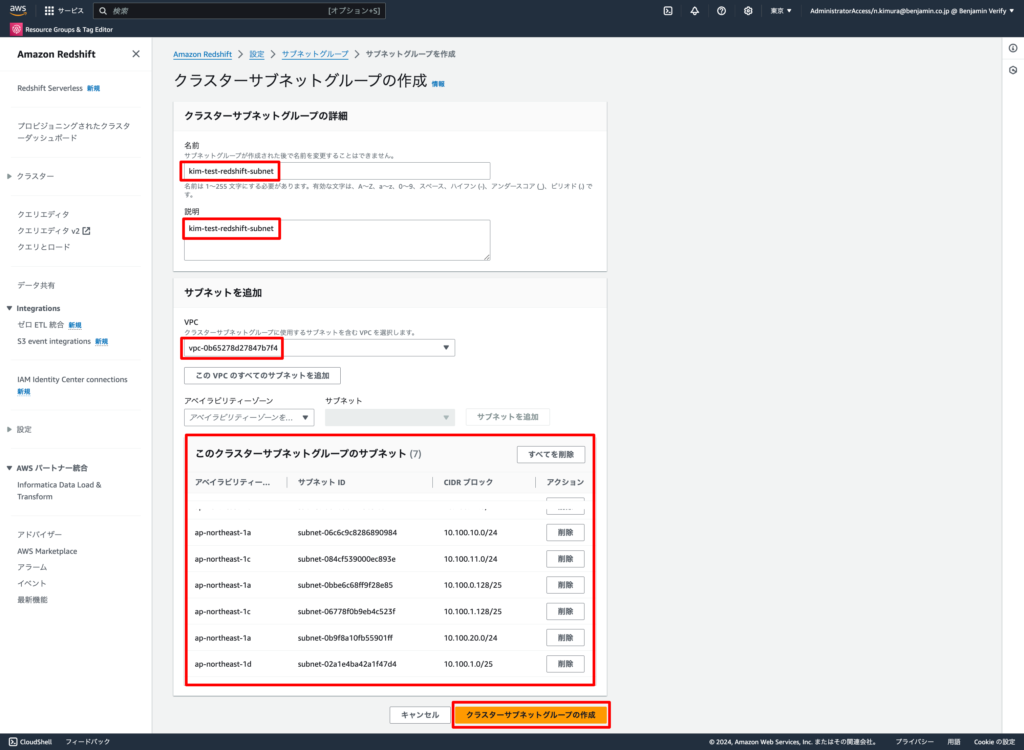
2-2. 左ペインの「設定」→「サブネットグループ」から「クラスターサブネットグループの作成」をクリックする
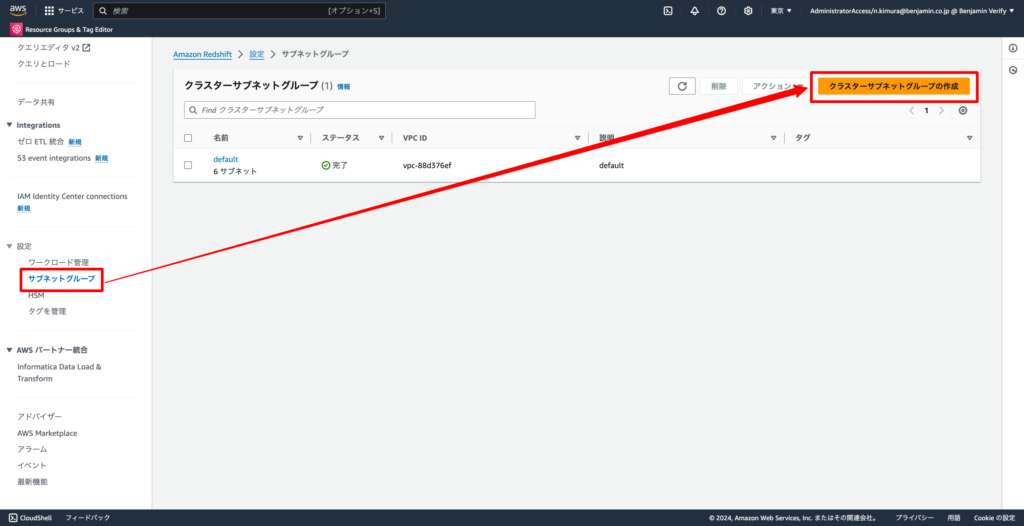
2-3. 下記の通り設定し、「クラスターサブネットグループの作成」をクリックする
- 名前: 任意のクラスターサブネットグループ名
- 説明: 任意の説明
- VPC: Redshiftを紐付けるVPC
- クラスターサブネットグループに紐づけるサブネット: Redshiftを紐付けるサブネット
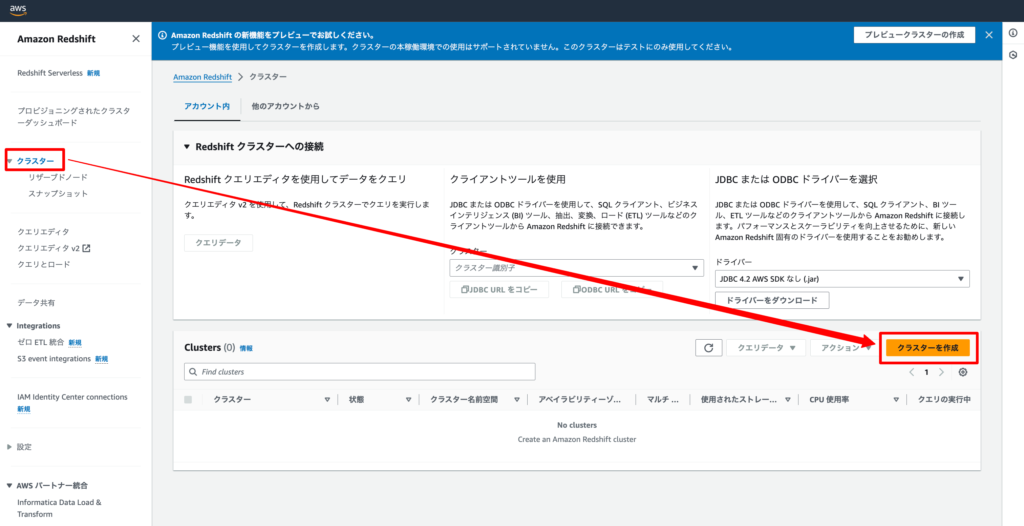
2-2.「クラスターを作成」をクリックする
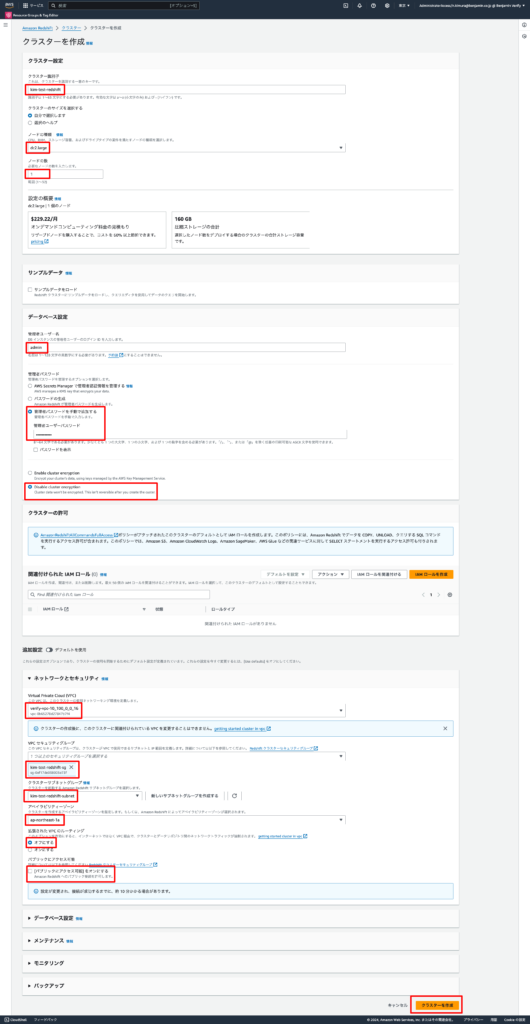
2-4. 下記の通り設定し、「クラスターを作成」をクリックする
- クラスターの基本設定
- Cluster identifier: 任意のクラスター名
- Node type:
dc2.large(小規模テストに適している) - Nodes:
1(シングルノードを選択) - Master username: 任意のユーザー名
- Master user password: 任意の安全なパスワードを設定
- 暗号化キー: Disable cluster encryption
- 追加設定(ネットワークとセキュリティのみ)
- VPC: 項番2-3でクラスターサブネットグループに紐付けたVPC
- セキュリティグループ: 項番1の事前作業で作成したセキュリティグループ
- クラスターサブネットグループ: 項番2-3で作成したクラスターサブネットグループ
- 拡張されたVPCルーティング: オフ
- パブリックアクセス: オフ
3. クラスターへの接続
3-1. 左ペインの「クエリエディタ v2」をクリックする
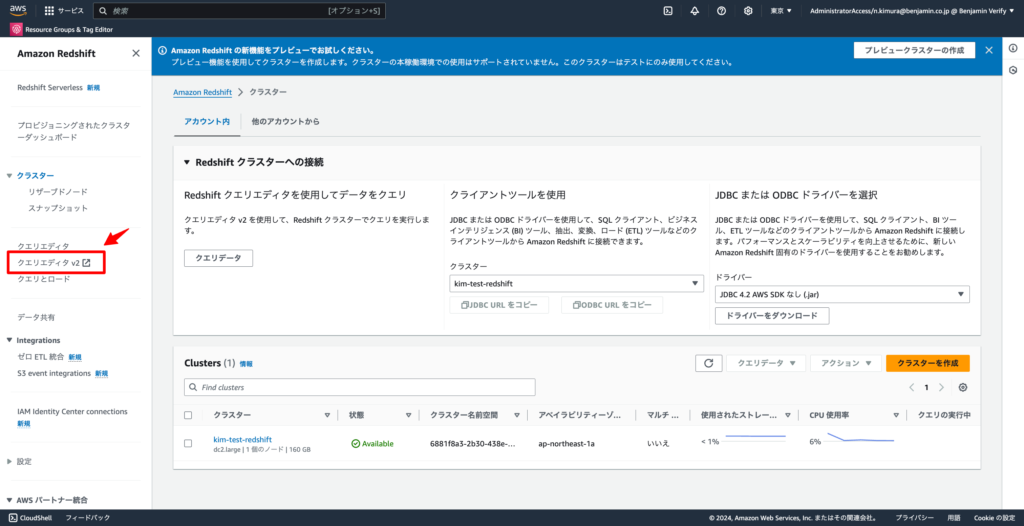
3-2. 項番2で作成したRedshiftをクリックする
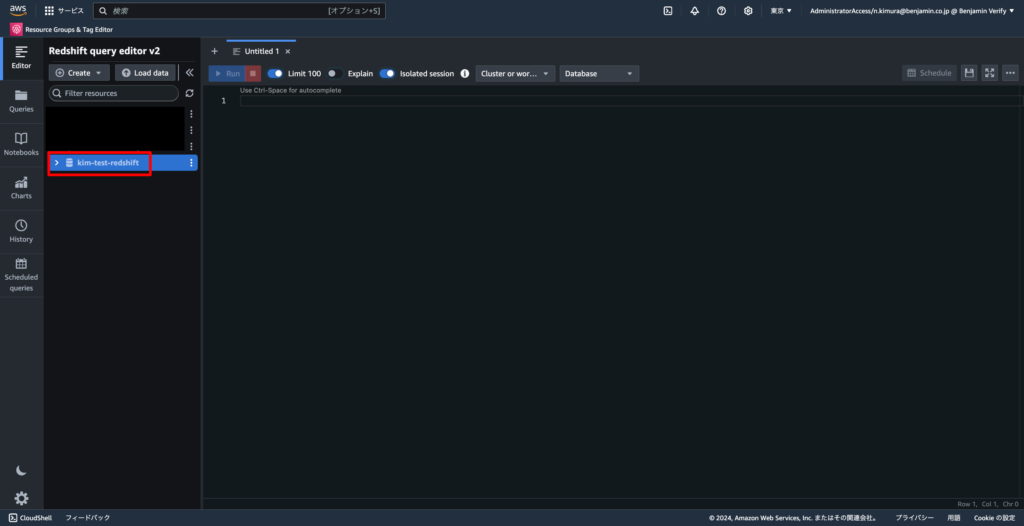
3-3. 下記の通りRedshiftへの接続設定を行い、「Create connection」をクリックする
- Other ways to connect: Database user name and password
- Database: dev(項番2で何も設定しなければdefaultでdevと設定される)
- User name: 項番2-4で設定したユーザー名
- Password: 項番2-4で設定したパスワード
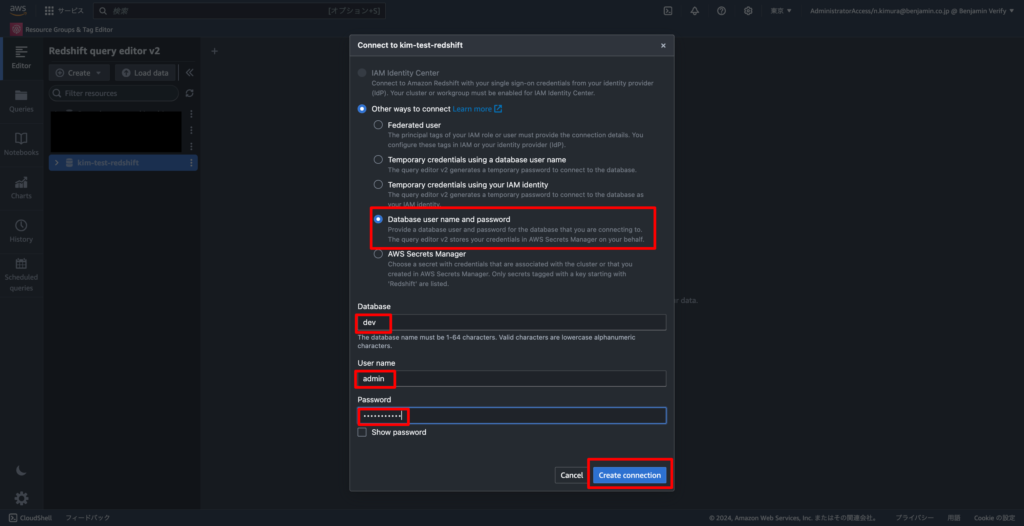
3-4. awsdatacatalogなどredshift配下にディレクトリが表示されれば接続完了
4. テーブルの作成とデータのロード
添付写真のようにSQLを記載し、「Run」ボタンより実行していきます。ここでは実行するSQL文のみ記載させていただきます
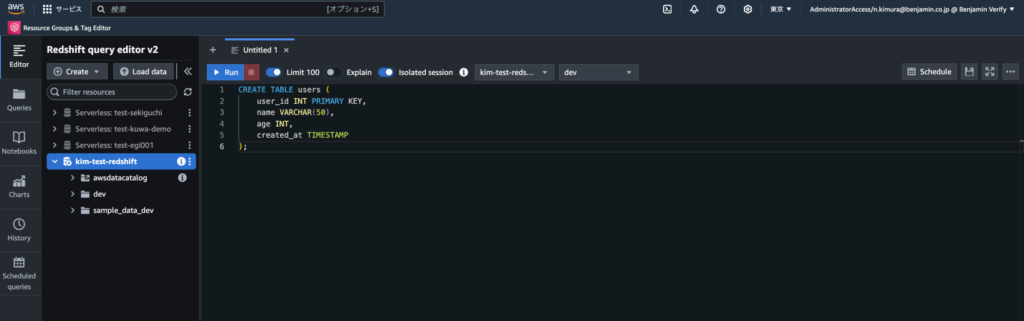
4-1. 下記SQLを実行し、テーブルを作成する
CREATE TABLE users (
user_id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
created_at TIMESTAMP
);4-2. 下記SQLを実行し、データを挿入する
INSERT INTO users (user_id, name, age, created_at)
VALUES
(1, 'Alice', 30, '2024-01-01 10:00:00'),
(2, 'Bob', 25, '2024-01-02 11:00:00'),
(3, 'Charlie', 35, '2024-01-03 12:00:00');
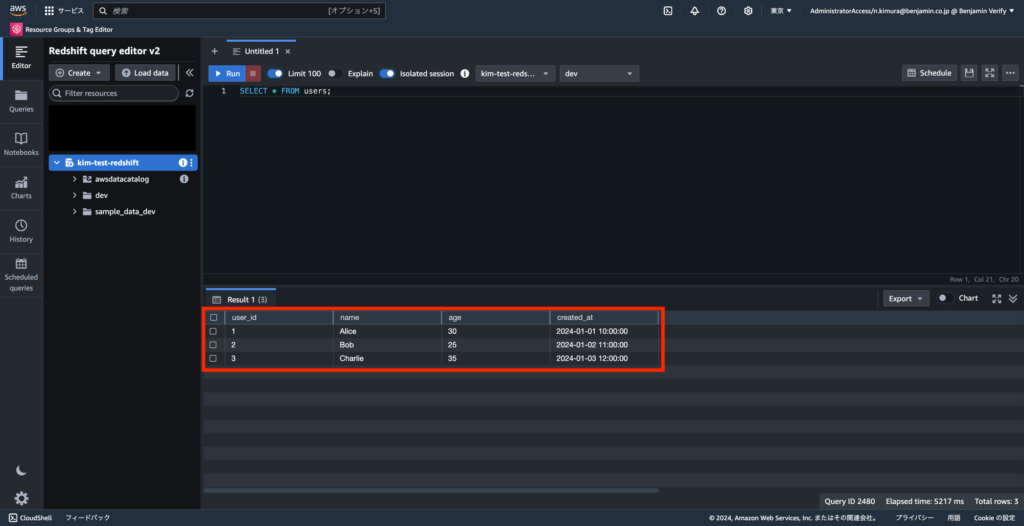
4-3. データを確認する
SELECT * FROM users;下記の通りレコードが確認できればOK
5. COPYコマンドで大量データをロード
5-1. ローカルで以下の内容を持つCSVファイル(例: users.csv)を作成する
user_id,name,age,created_at
4,David,40,2024-01-04 13:00:00
5,Eve,28,2024-01-05 14:00:00
6,Frank,33,2024-01-06 15:00:005-2. S3バケットを作成し、作成したCSVファイルをアップロードする
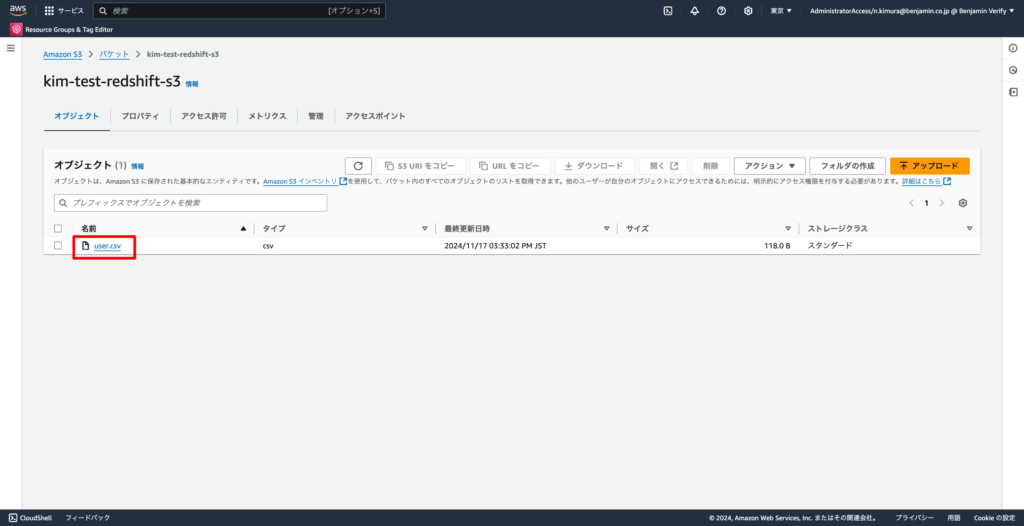
※S3バケットの作成手順については下記AWS公式ページをご確認ください。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/create-bucket-overview.html
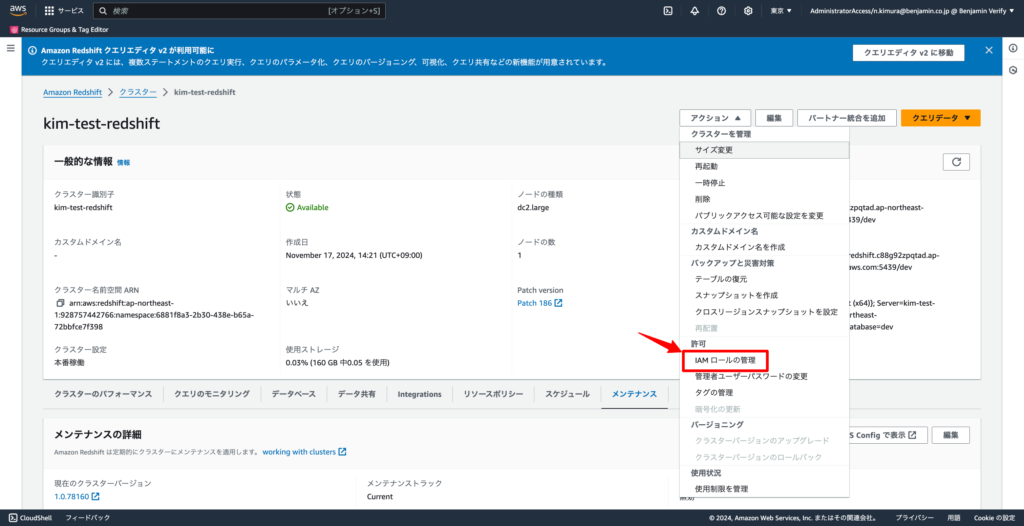
5-3. RedshiftにS3にアクセスする権限を持ったIAMロールを設定する
AmazonS3ReadOnlyAccessポリシーを持つIAMロールを作成し、Redshiftに紐づけます。
作成したRedshiftのコンソール画面より、「アクション」→「IAMロールの管理」を選択することで、IAMロールを紐づけることができます
※IAMロールの作成については、下記AWSの公式ページよりご確認ください。
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_create.html
5-4. COPYコマンドでデータをロードする
項番4で接続設定した、クエリエディタv2より下記SQLを実行してください。
COPY users
FROM 's3://<your-bucket-name>/users.csv'
IAM_ROLE '<your-iam-role-arn>'
CSV
IGNOREHEADER 1;5-5. ロード結果を確認する
S3に保存したCSVファイルの内容が追加されていれば成功です。
SELECT * FROM users;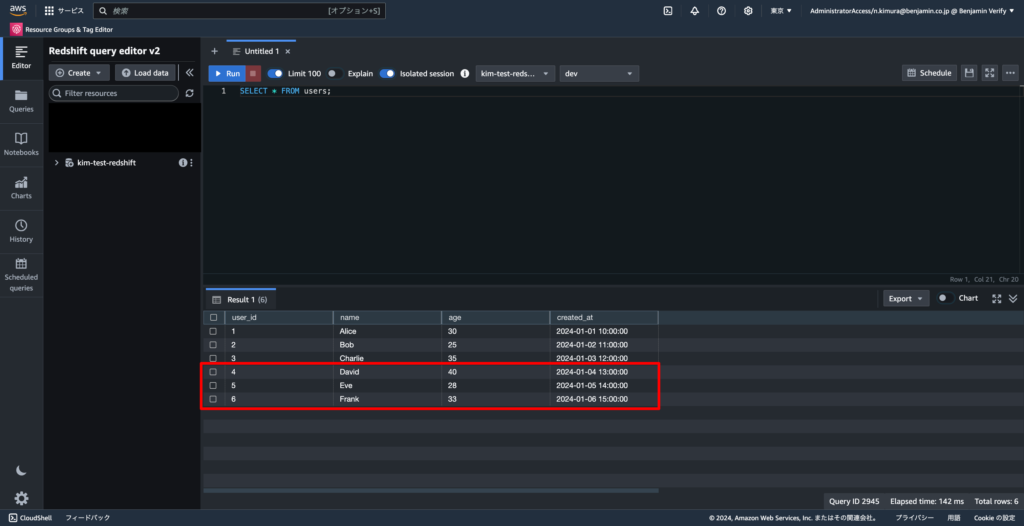
6. クエリの最適化
ソートキー、分散スタイルを設定することで、クエリを最適化することができます。それぞれの設定の意味については下記にて説明させていただきます。
- ソートキー
クエリの WHERE 条件や BETWEEN, >=, <= などで頻繁に使用される列がある場合、ソートキーを指定すると効率が向上します。今回は
例)sales テーブルで sale_date を基準にしたクエリが多い場合:
SELECT * FROM sales WHERE sale_date > '2024-01-01';今回は日付がwhere句で条件が絞られることを想定してcreated_atをソートキーとして指定します。
- 分散スタイル(DISTSTYLE)
分散スタイル(DISTSTYLE) は、Amazon Redshift におけるデータの配置方法を決定する重要な設定で、適切に選択することでクエリ性能が大幅に向上します。
今回はuser_idがjoinやwhereなどで使われることを想定して、KEY分散のスタイルを指定します。
| 分散スタイル | 特徴 | 利用シーン |
| AUTO分散 | テーブルサイズやクエリパターンに基づいて動的にEVEN、KEY、ALLのいずれかを自動選択する。 | 初期段階でクエリパターンが明確でない場合。 |
| EVEN分散 | データをランダムに均等に分散。 | 特定の列に基づく結合やフィルタリングが少ない場合、汎用的に使用可能。 |
| ALL分散 | 全ノードに全データを複製。 | テーブルサイズが小さく、頻繁に他のテーブルと結合される場合に使用。 |
| KEY分散 | 指定した分布キーの値に基づき、ハッシュ計算でノードに分散。 | テーブル間で同じキーを基準に結合(join句)やフィルタリング(where句など)を行うクエリが多い場合に最適。 |
※デフォルトではAUTO分散が選択されていますが、今回分散スタイルの選択方法を学ぶため、KEY分散を選択して最適化を実施していきます。
6-1. ソートキーと分散キーの設定
項番2で接続設定したクエリエディタv2で以下SQLを実行してください。
CREATE TABLE users_optimized (
user_id INT,
name VARCHAR(50),
age INT,
created_at TIMESTAMP
)
DISTSTYLE KEY
DISTKEY (user_id)
SORTKEY (created_at);6-2. usersテーブルよりデータをコピーする
INSERT INTO users_optimized
SELECT * FROM users;6-3. 統計情報の更新
ANALYZE users_optimized; COPYコマンドを使用してデータをロードした際、データの分布が不均一になる場合があります。そのため次項のEXPLAINコマンドを実行すると、下記のようなエラーが発生してしまします。これを整えるために、上記コマンドを実行します。
----- Tables missing statistics: users_optimized -----
----- Update statistics by running the ANALYZE command on these tables -----
6-4. クエリの実行計画を確認
EXPLAIN SELECT * FROM users_optimized WHERE user_id = 1;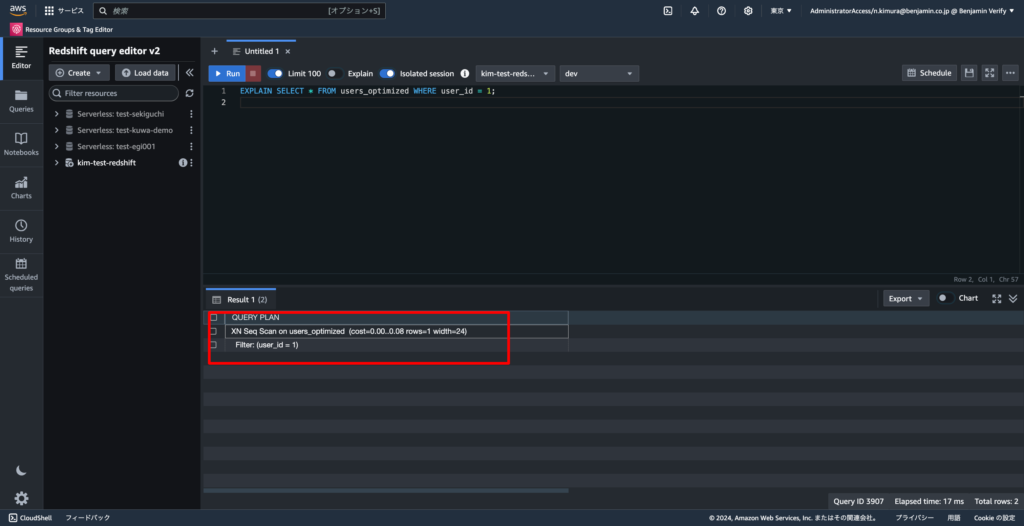
EXPLAINは、データの実行計画を表示するコマンドです。これにより、Redshiftがどのテーブルやインデックスにアクセスしているか、どの順番で処理が行われるかや、どれくらいコストが掛かって、データ幅がどれくらいで…を測ることができます。
今回は下記の通りの情報が取れます。
- XN: これは、実行計画のノードが 並列実行 であることを示しています
- Redshiftでは並列処理を使用することが多いため、この表記が使われます
- cost=0.00..0.08: これはクエリ実行のコストを示しており、
0.00はスキャン開始時のコスト、0.08は実行が完了するまでの推定コストです - rows=1: クエリが返すと予測される行数です
- width=24: 各行のデータ幅(バイト単位)です
- Filter: (user_id = 1): これは、
WHERE句に基づいてフィルタリングが行われていることを示します。
6-5. パフォーマンスの確認
まずはusers_optimizedテーブルに下記SQLを実行してみましょう!
SELECT * FROM users_optimized WHERE user_id = <特定のID>次にusersテーブルに下記SQLを実行してみましょう!
SELECT * FROM users WHERE user_id = <特定のID>左ペインにあるQuery Historyを見ると、実行時間が少し最適化されたテーブルの方が早いので、ソートキー、分散スタイルを設定する方がパフォーマンスが改善されると言えます。

7. Redshiftの削除
今回作成したプロビジョンドタイプのRedshiftはUSD 0.25/時コストがかかります。ハンズオン終了時は下記手順で削除を実施してください。
7-1.「作成したRedshiftを選択」→「アクション」→「削除」
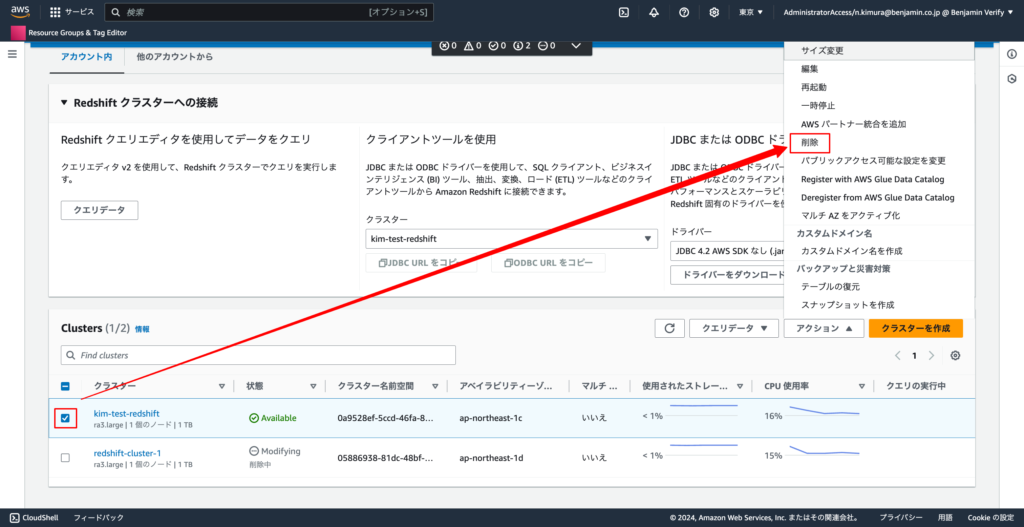
7-2. 「最終スナップショットを作成」のチェックを外し、フォームに「削除」と入力し、「クラスターを削除」のボタンをクリックする
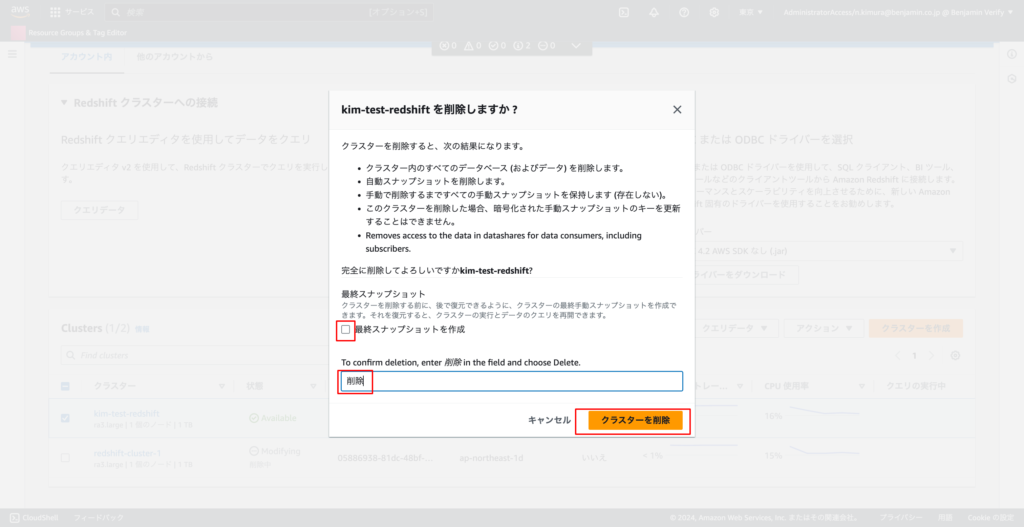
クラスターの一覧から作成したクラスターが消えれば、削除完了!
まとめ
いかがでしたでしょうか?
今回はRedshiftの理解が深まるようにハンズオンを作成しました。これを実施すれば、Redshiftの簡単な操作はできるようになるはずです。
今年導入されたAWS DEAの試験にもこちらの範囲は出ると思いますので、よければ実施していただけますと幸いです。