【Amazon Bedrock】OpenSearch Serverlessを使ってRAGチャットを簡単構築してみた
こんにちは。ベンジャミンの小谷です。
今回は、Amazon Bedrockのナレッジベース機能を活用して、自社の情報を質疑応答できる簡単なチャットアプリを構築するハンズオンをご紹介します。
AWS Bedrock上ではいくつかのナレッジベース機能が用意されていますが、当ブログではAmazon OpenSearch Serverlessを使用します。
ベクトルストアにOpenSearch Servelessを使用することで、簡単かつすぐにRAGチャット環境を構築することができます。
目次
- はじめに
- 前提条件・準備
- 実際に構築してみる
- 動作テスト
1. はじめに
構築作業を実施する前に、RAGチャットボット機能を構築するにあたり、必要な前提知識をいくつか説明します。
RAG(Retrieval-Augmented Generation)とは、大規模言語モデル(LLM)の回答精度を向上させる技術です。
LLMが持つ一般的な知識に加えて、特定のドメインやビジネスに関する情報を検索することで、より正確で信頼性の高い回答を生成できます。
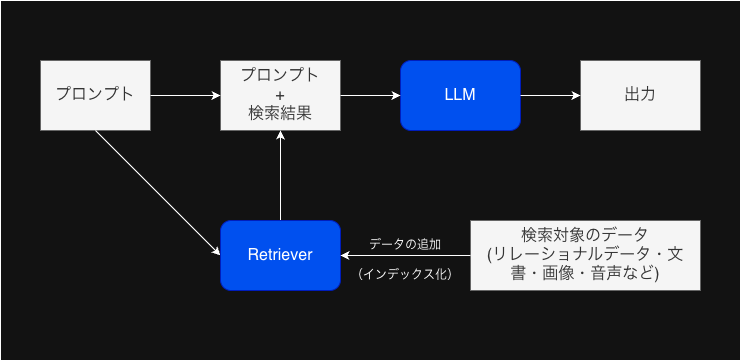
上記のイメージで、LLMに対してRetrieverと呼ばれるコンポーネントが検索した背景情報を同時に入力することで、LLM自身が持つ知識を強化します。
Retrieverが検索するデータソースとして社内の機密情報やビジネスに関する情報を構築することで、LLMが自身で持っていない知識を活用して回答を出力することが出来ます。
Amazon Bedrock Knowledge Baseでは、AWS上のデータソースを使ってRAG環境を構築するマネージドサービスが提供されています。
ベクトルストアとしてOpenSearch Servelessを選択する主なメリットは以下となります。
- サーバーレス: インフラ管理が不要
- 自動スケーリング: トラフィックに応じて自動拡張
- セットアップが非常に簡単
- 使った分だけの従量課金
ただし、1つ注意点として、OpenSearch Servelessは使用した時間に応じてコストが加算される従量課金制となっています。
使っていなくても存在するだけで高額な費用が発生してしまうため、個人学習等で利用される場合には後片付けに十分注意してください。
2. 前提条件・準備
まず、ナレッジベースのデータソースとなるS3バケットを準備します。
- S3バケットを作成(例:
bedrock-demo-2025) - ナレッジソースとなるファイルをアップロード
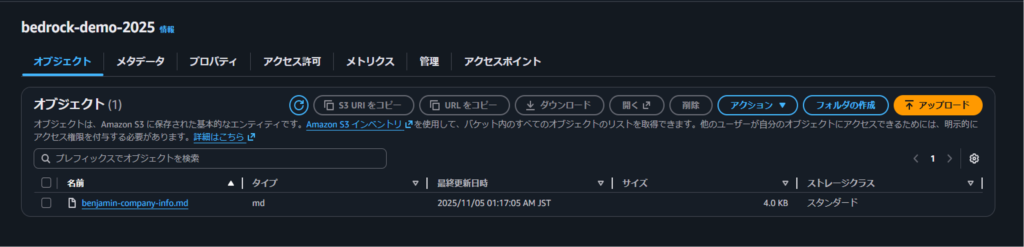
今回は、会社情報をまとめたMarkdownファイル(benjamin-company-info.md)をアップロードしました。
データソースの配置にあたり、以下の点に注意してください。
- リージョン: S3バケットとBedrockナレッジベースは同じリージョンに配置する必要があります。
- ファイルサイズ: 大きすぎるファイルは事前に分割することが推奨されています。
- データのクリーニング: 不要な情報を除去し、見出しや段落を明確にしておくと検索精度が向上します。
今回の検証では、ベンジャミンのWebサイトの会社概要をClaudeに要約させて作成したMDファイルをS3に配置しました。
# 株式会社ベンジャミン 企業情報
## 会社概要
- **会社名**: 株式会社ベンジャミン(Benjamin Inc.)
- **略称**: BJM
- **代表者**: 代表取締役 川尻 純
- **設立**: 2017年6月
- **本社所在地**: 東京都中央区日本橋久松町6番地9号 AS ONE日本橋Eastビル4階
- **資本金**: 358万円
- **従業員数**: 35名(役員含め38名)+ ベトナム支店12名(2025年6月現在)
- **企業理念**: 「誠実」「信頼」(ベンジャミンという植物の花言葉に由来)
## 事業内容
株式会社ベンジャミンは、AWS(Amazon Web Services)を中心としたクラウドソリューションとSalesforce導入支援を主力とするシステム開発会社です。
### 主要サービス
1. **システム開発受託サービス・運用保守**
- 業務システム、Webシステムの開発
- 要件定義から構築・運用まで一貫対応
2. **AWS構築・支援・最適化サービス**
- AWSクラウド環境の設計・構築
- サーバレスアーキテクチャ設計
- インフラ構築から運用保守までワンストップ対応
- コスト最適化提案
3. **Salesforce導入支援・開発**
- SalesCloud、Account Engagement(Pardot)
- カスタマイズおよび外部システム連携
4. **自社サービス開発**
## AWS関連の強みと認定資格
### パートナーランクと認定
- **AWSアドバンストティアサービスパートナー**(2021年12月認定)
- **AWS生成AIコンピテンシー**(2025年8月取得・国内4社目)
- **AWS内製化支援パートナー**(2024年認定)
- **AWSソリューションプロバイダー(SPP)資格**保有
- **AWS Cloud Native Builders Group**認定(2022年)
- **AWS SDP(ECS)**取得(2024年)
### 技術的特徴
- AWS認定資格保有者が社員の2/3以上在籍
- サーバレス技術を活用したモダンな開発が得意
- 生成AI(Amazon Bedrock、QuickSight等)の実績多数
- フルスタックエンジニアが在籍(インフラからアプリまで対応可能)
### 最新サービス
**AWSスタートアップパッケージ**(2025年6月提供開始)
- AWS初期設定から運用、AI活用、内製化支援まで包括的にサポート
- スタートアップ企業や中小企業のAWS活用を加速
## Salesforce関連
- **Salesforceベースコンサルティングパートナー**認定
- SalesCloudコンサルタント資格保有者在籍
- SalesCloud、Account Engagement(Pardot)に知見と実績
## 技術領域と実績
### 得意分野
- クラウドネイティブ開発
- サーバレスアーキテクチャ
- 生成AI活用(社内ナレッジ検索、ドキュメント自動生成等)
- IoT案件
- PoC(概念実証)案件
- SPA(Single Page Application)化
- PWA対応
### 主要取引実績
- コニカミノルタ様(AWS生成AI案件)
- 岩崎電気様(AWS生成AI案件)
- NTTプレシジョンメディシン様(AWS生成AI案件)
- メタジェンセラピューティクス様
- センキョ様
### プロジェクト特性
- 受注案件の9割以上がプライム案件(直接契約)
- 中規模から大規模システム開発に対応
- 要件が不明確なプロジェクトでも技術提案しながら推進可能
## 拠点情報
- **本社**: 東京都中央区(関東圏内往訪対応可能)
- **支社**: 愛媛県松山市(四国地域のサポート対応)
- **R&D拠点**: ベトナム(2022年3月設立・先端技術研究開発)
## その他の特徴
- プライバシーマーク付与事業者(第10825098(01)号)
- リモートワーク対応可能
- 「エンジニアが報われる会社」を企業理念として設立
- 最新技術のキャッチアップが速い
- 柔軟な対応とプロジェクトマネジメント力に強み
## 問い合わせ
- **公式サイト**: https://benjamin.co.jp/
- **担当部署**: Sales & Marketing Group※ 要約時に過去の情報が混入しているため、この後のチャットボットからの回答に古い情報が含まれてしまっています。
RAGにデータソースを登録する際は、古い情報や誤った情報が含まれていないことをレビューしていただくことをお勧めします。
3. 実際に構築してみる
Bedrockコンソールから「ナレッジベース」を選択し、新規作成を開始します。
ステップ1では、ナレッジベースの基本情報を設定します。
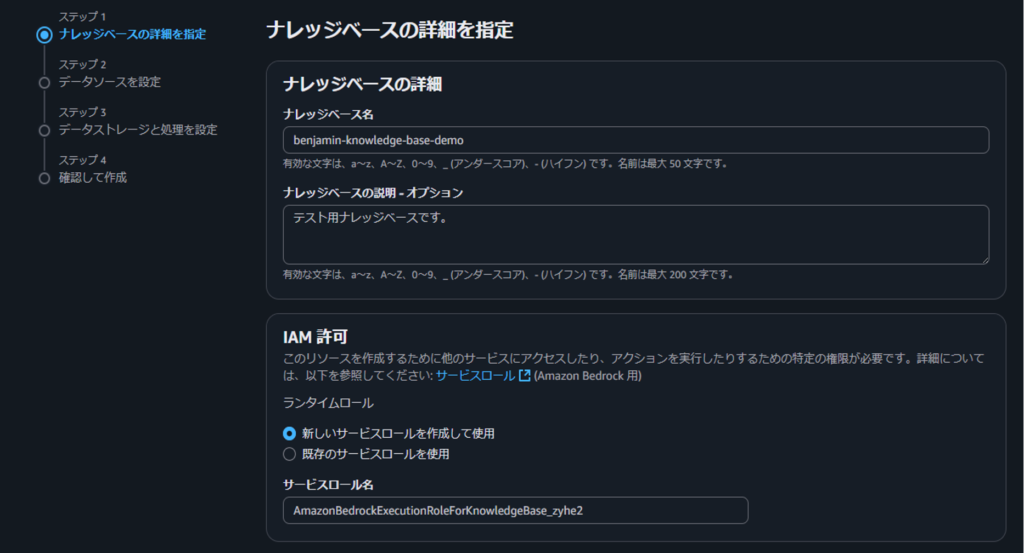
| 項目 | 設定値 |
|---|---|
| ナレッジベース名 | benjamin-knowledge-base-demo |
| 説明 | テスト用ナレッジベースです。 |
| IAMサービスロール | 新しいサービスロールを作成 |
| ロール名 | AmazonBedrockExecutionRoleForKnowledgeBase_zyhe2 |
| ナレッジベースタイプ | ベクトルストアを含むナレッジベース |
ステップ2では、データソースの設定を行います。
MDファイルをアップロードしたS3バケットを指定して入力を進めてください。
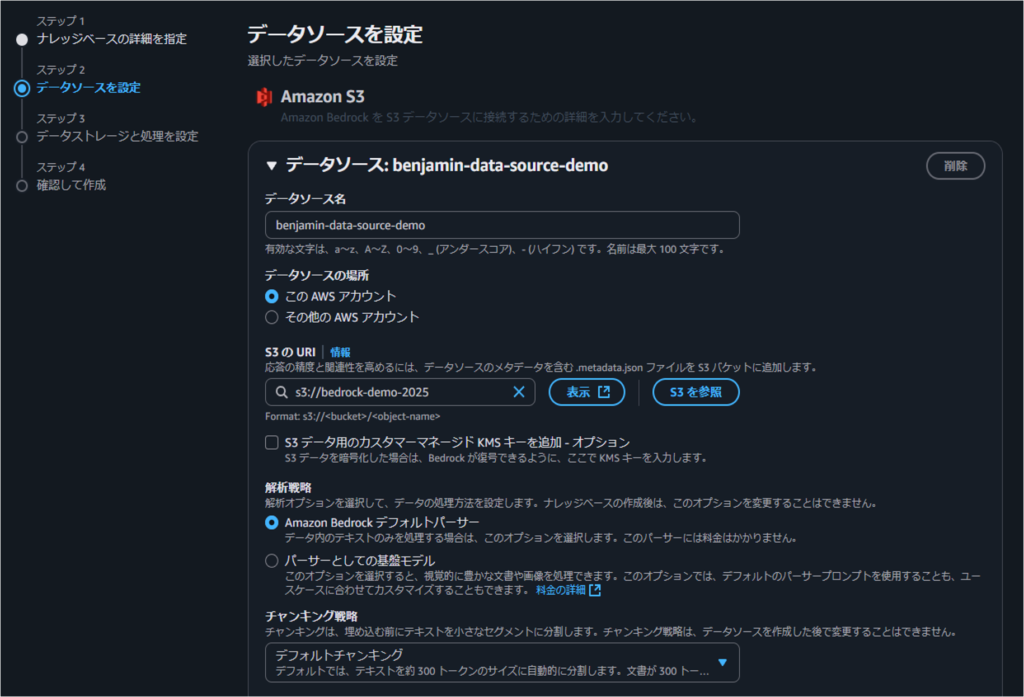
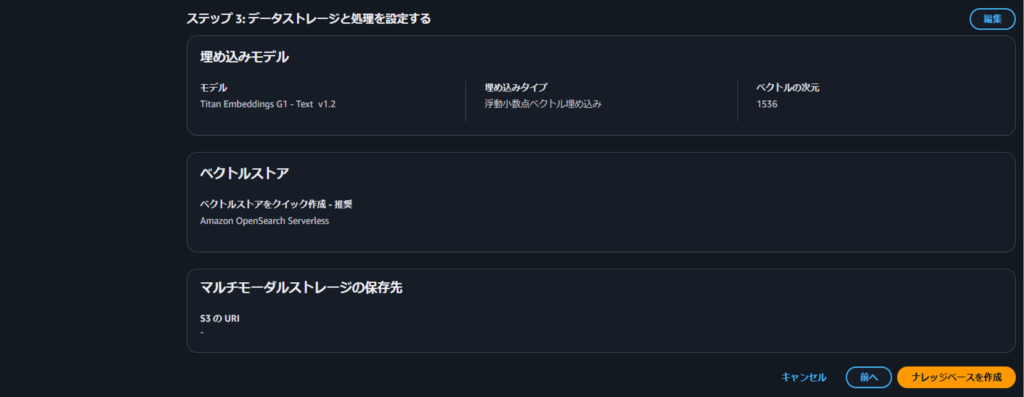
ステップ3では、データストレージと処理を設定します。
今回は埋め込みモデルとして、比較的に低コストで利用できるTitan Embeddings G1 – Text v1.2 を指定しました。
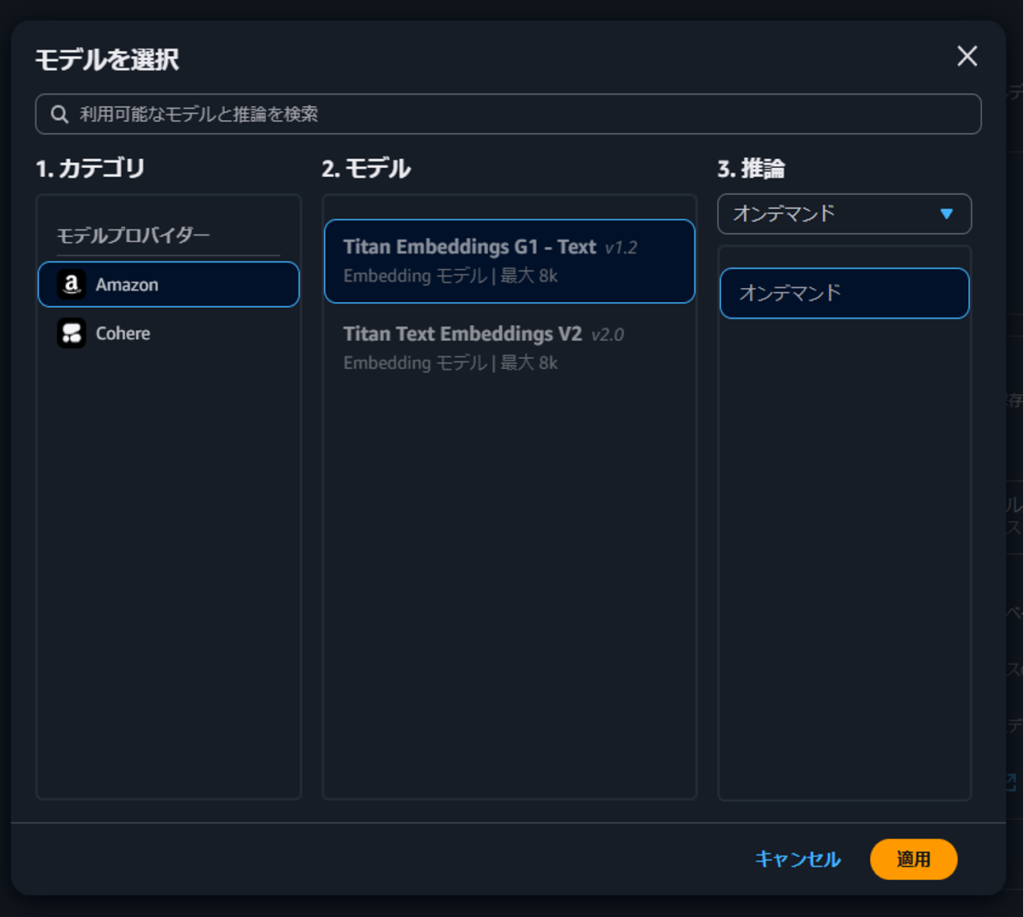
ベクトルストアの設定で、OpenSearch Serverlessをベクトルストアとして選択します。
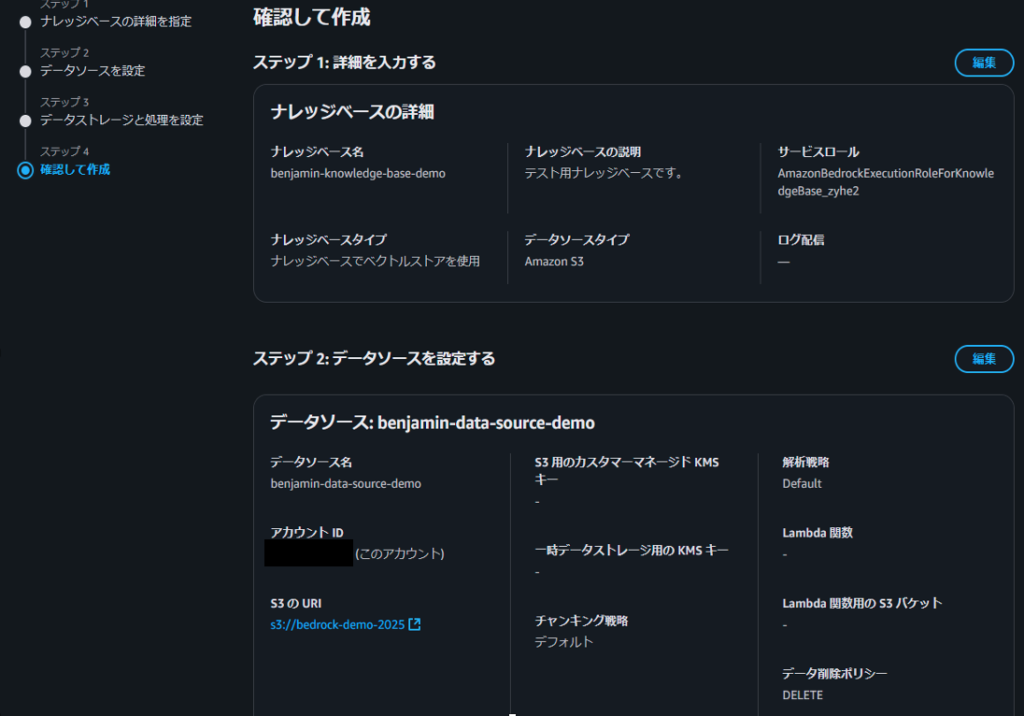
ステップ4で、すべての設定項目を確認します。
問題がなければ、「ナレッジベースを作成」を押下してください。
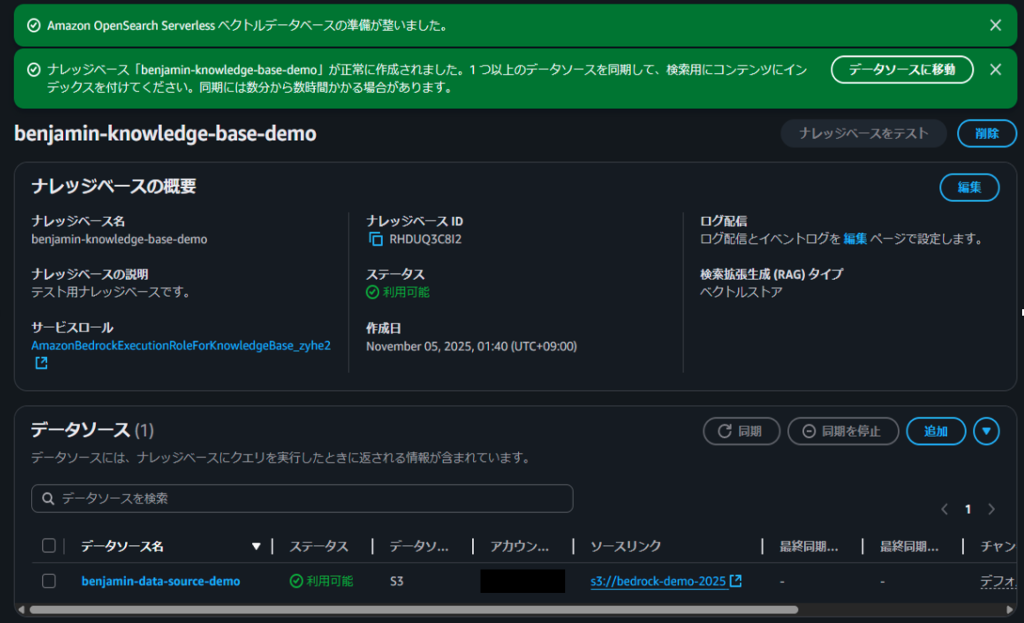
作成が完了したら、成功メッセージが表示されます。
プロビジョニングに5〜10分程度かかるため、しばらく待機してステータスが「利用可能」になったことを確認してください。
ステータスが更新されたら、データソースを同期してコンテンツにインデックスを付ける必要があります。「データソースに移動」ボタンをクリックし、同期を実行します。
同期に成功したら、OpenSearch Servelessによるナレッジベースの環境構築が完了となります。
4. 動作テスト
ナレッジベースが作成できたら、コンソールのテスト機能で動作確認を行います。
右上の「ナレッジベースをテスト」を押下してテスト機能画面に移動してください。
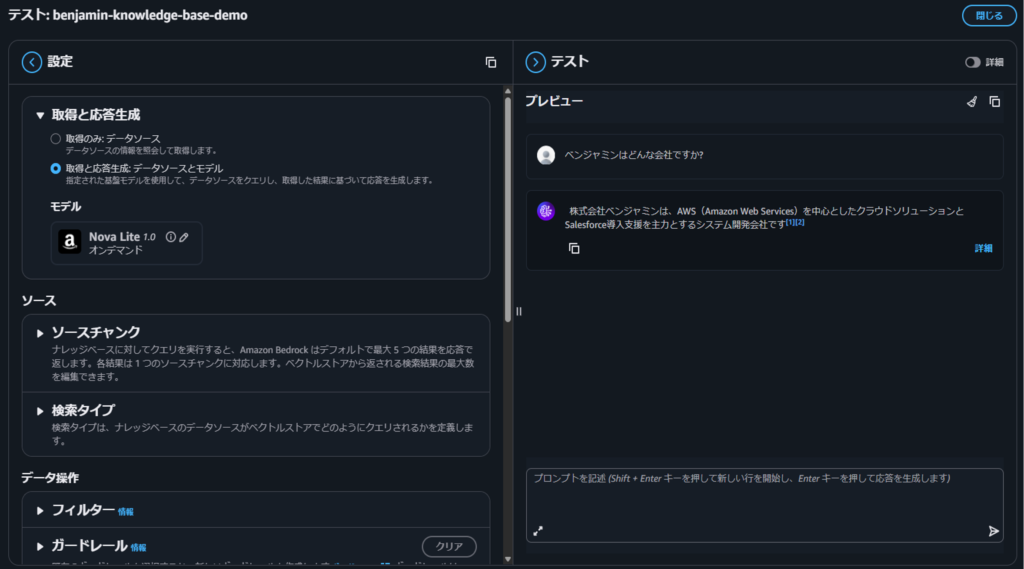
モデルを選択して、右側のチャット画面でテストを実施します。
コストを考慮して軽量の「Nova Lite」を選択しましたが、高品質な回答を検証する場合は「Claude」等のフロンティアモデルを選択してください。
以下、実際にテストを実施した結果を記載します。
ナレッジベースに登録したデータソースによって結果が変わるため、内容を調整して検証してみてください。
※
質問1: 「ベンジャミンはどんな会社ですか?」
回答:株式会社ベンジャミンは、AWS(Amazon Web Services)を中心としたクラウドソリューションとSalesforce導入支援を主力とするシステム開発会社です[1][2]
↑ 引用元がナンバリングされ、ソース文書へのリンクも表示されます。
質問2: 「生成AIの実績を教えてください」
回答:生成AIの主な実績は、社内ナレッジ検索、ドキュメントの自動生成、IoT案件などです
質問3: 「拠点はどこにありますか?」
回答:本社は東京都中央区、支社は愛媛県松山市、R&D拠点はベトナム(2022年3月設立)
質問4: 「Salesforceの対応は可能ですか?」
回答:Yes, Salesforce can be supported by Benjamin. Benjamin offers Salesforce implementation support and development services, including customization and external system integration…
所感としては、概ねMDファイルに記載した情報をベースに想定通りの回答が生成出来ていますが、一部の回答で誤った情報が出力されているなといった印象です。
生成AIの実績を聞いているのに、IoT関連の情報を出力している状態については、LLMをより高性能なモデルに変更するなど改善の余地はありそうです。
最後に
いかがでしたでしょうか?
OpenSearch Servelessでは、基本的にコンソールの表示通りに選択することで、簡単に動作可能なナレッジベースの構築が可能です。
作成したナレッジベースを活用して、Bedrock APIによるアプリケーション統合の実装方法などをご紹介したいと思います。
なお、OpenSearch Servelessは従量課金となるため、使用状況に関わらず時間で課金されます。
テストが完了したら、ナレッジベース詳細画面の「削除」とS3に配置したデータソースの整理を忘れずに実施してください!